I have seen a decent amount of software developed via vibe coding, i.e., coding with heavy AI assistance but I have not seen anything that is passable as professionally-developed software. One big tell is that the AI assistant tends to add in copious boundary condition checks that’d never occur to humans because they are unlikely to occur in practice. Another is bizarre style, which imposes a heavy cognitive cost on the reader (whose time is qualitatively more valuable than that of the computer).
For people who basically can’t code anywhere near a professional level, I see why this is valuable, but I think these people should be honest with themselves and admit they can’t really code, and wouldn’t know good code if it hit them in the face.
For people who can (and who can already avail themselves of various autocompletion tools whether AI-powered or knowledge-based), I don’t see the value proposition. It creates hard-to-review code and code review is a more difficult, important, cognitively taxing, and rarified skill than development itself, so this technology could, in the worst case, actually drive up the already high cost of software development.
Category: Language
In memoriam: Eugene Buckley
It was just announced that Gene Buckley has passed away. I took nearly all of his classes in graduate school, TAed for him, and he served on my dissertation committee, so he definitely had a profound influence on me and my work. I particularly remember his seminar on opacity, which introduced me to substance-free phonology, and his seminar on Kashaya, where I learned about the ancient, mysterious i → d / _ u rule and the many Russian loanwords from their contact with Fort Ross (e.g., [jaːpalka] ‘apple’ < яблоко, with devoicing, stress-conditioned lengthening, and CV-metathesis). Gene was an island of relative sanity and calm during my turbulent grad school year. He’ll be missed.

[Gene’s colleague Rolf Noyer wrote a brief memorial here.]
How not to acquire phonological exchanges
I recently gave a talk at the Canadian Linguistic Association (sort of like the LSA, but Canadian and frankly a lot better because it doesn’t have nearly as many prominent crackpots and cranks) with Charles Reiss on the notion of “exchange rules” as they’re understood in Logical Phonology (LP). Whereas SPE-era theories can use alpha-notation to generate exchange rules, LP can model exchange processes via a series of seemingly complex rules, either via a Duke of York gambit or opportunistic abuse of underspecification. Since it seems quite likely that purely phonological exchanges don’t in fact exist, we suggest that the language acquisition device is constrained so as to not profer analyses of those types, though we also consider that this may be an accident of the “diachronic filter” of the sort developed by Ju. Blevins, M. Hale, and J. Ohala. The handout is here for those interested, and like other things we’ve been writing about LP, will probably be included in a forthcoming book. One interesting question that we raise, but don’t answer, is what one ought to do about exchanges in Optimality Theory. Alderete (2001), for example, proposes to model them with a family of “anti-faithfulness constraints”. While one could predict the absence of exchanges by eliminating this constraint family, Alderete also uses anti-faithfulness for phenomena other than exchanges, and some of these may be more robustly attested; it’s not clear what ought to be done thus.
References
Alderete, J. 2001. Dominance effects as transderivational anti-faithfulness. Phonology 18: 201-253.
Guest & Martin on neural networks as cognitive models
In our “big questions” class, we read a few papers about whether large artificial neural network language models are good (or even candidate) cognitive models. As part of my background reading I also reviewed this recent paper by Guest & Martin (2023). The crux of the paper is an argument based on simple propositional logic, and because it was hard for me to follow, I thought I’d try to review it here.
G&M first identify a commonly, mostly implicit argument for studying artificial neural networks as cognitive models which takes the form of modus ponens. I will take the liberty of generalizing it considerably here.
- $P \rightarrow Q$: if neural networks (i.e., their outputs) are correlated with behavioral or neuroimaging data, they are plausible cognitive models (“do what people do”).
- $P$: neural networks are correlated with such data.
- $\vdash Q$: therefore they are plausible cognitive models.
G&M give several examples where this argument has been applied and this is the exact motivation that linguists engaged in “LLMology” tend to give during the question period. The problem, as G&M note, is that the correctness of this inference depends crucially on whether $P \rightarrow Q$, and there are no shortage of arguments against that proposition. The most obvious one, of course, is the possibility of multiple realizability. They use the example of two clocks are behaviorally quite similar, but one is actually based on springs and cogs whereas the other has a quartz motion powered by a battery. Clearly, neural networks and human brains could both realize the same sorts of behaviors/mappings without being internally the same.
G&M continue that if the above inference is valid, it should be possible to apply modus tollens to it as well. This has the following general form.
- $P \rightarrow Q$: (as above).
- $\neg Q$: neural networks are not plausible cognitive models.
- $\vdash \neg P$: therefore neural networks (i.e., their outputs) are not correlated with behavioral or neuroimaging data.
G&M give several examples where such an argument could easily be applied: so-called hallucinations, cases where neural networks continue to underperform humans when provided with reasonable amounts of data, as well as cases where neural networks can be shown to exhibit superhuman performance! As they conclude: “Even though $Q$ can, and often does, fail to be true, we, as a field, do not formulate its relationship to $P$ in terms of MT [modus tollens]. (G&M: 217). Rather, they argue, what people actually do is show that:
- $Q \rightarrow P$: if the neural networks are plausible cognitive models (“do what people do”), then neural networks are correlated with behavioral or neuroimaging data
Using this to assert $Q$, of course, is the fallacy of affirming the consequent, and is clearly invalid. What G&M ultimately seem to conclude is that little can be logically concluded from cognitive modeling with artificial neural networks, even if these models remain “useful” in many domains.
References
Guest, O., and Martin, A. E. 2023. On logical inference over brains, behaviour, and artificial neural networks. Computational Brain & Behavior 3:213-227.
Cajal on “diseases of the will”
Charles Reiss (h/t) recently recommended me a short book by Santiago Ramón y Cajal (1852-1934), an important Spanish neuroscientist and physician. Cajal first published the evocatively titled Reglas y Consejos sobre Investigación Cientifica: Los tónicos de la voluntad in 1897 and it was subsequently revised and translated various times since then. By far the most entertaining portion for me is chapter 5, entitled “Diseases of the Will”. Despite the name, what Cajal actually presents is a taxonomy of scientists who do contribute little to scientific inquiry: “contemplators”, “bibliophiles and polyglots”, “megalomaniacs”, “instrument addicts”, “misfits”, and “theorists”. I include a PDF of this brief chapter, translated into English, here for interested readers, under my belief it is in the public domain.
“Indo-European” is not a meaningful typological descriptor
A trope I see in a lot of student writing (and computational linguistics writing at all levels) is a critique of prior work as being only on “Indo-European languages”, and sometimes a promise that current or future work will target “non-Indo-European languages”.
To me, this is drivel. The Indo-European language family is quite diverse; i.e., for the vast majority of things I’m interested in, either, say, Italian or Russian is sufficiently different from English to make a relevant comparison. And there are a huge number of “non-Indo-European” languages that are typologically similar to at least some Indo-European languages on at least some dimensions; i.e., Finno-Ugric, “Aquitanian” (i.e., Basque) and the (narrowly defined) “Altaic” families (Mongolic, Tungusic, and Turkic) have quite a bit in common typologically with IE, as do, say, Japanese and Korean. Genetic relatedness just isn’t that typologically informative in very dense, very “old” families like IE.
If you want to talk typology, you should focus on typological aspects actually relevant to your study rather than genetic relatedness. If you’re studying phonology, the presence of vowel harmony in the family may be relevant (but note that Estonian, despite being Finnic, does not have productive harmony); if you’re interested in morphology, then notions like agglutination may be relevant (though not necessarily). Gross word order descriptors (like “VSO”) are likely to be relevant for syntax, and so on.
In some cases, one of the relevant typological aspects is not language typology, but rather writing systems typology. There, genetic relatedness isn’t very informative either, because the vast majority of writing systems used today (and virtually all of them outside East Asia) are ultimately descended from Egyptian hieroglyphs. And we shouldn’t confuse writing system and language.
Linguists ought to know better.
NAPhC talk on Polish and Logical Phonology
I just gave a talk at NAPhCxiii in Montréal in which I used Logical Phonology to characterize major patterns in noun stem allomorphy. With assiduous use of underspecification, I am able to render these patterns largely exceptionless. The handout is on LingBuzz and LOA here.
How many Optimality Theory grammars are there?
How many Optimality Theory (OT) grammars are there? I will assume first off that Con, the constraint set, is fixed and finite. I make this assumption because it is one assumed by nearly all work on the mathematical properties of OT. Given the many unsolved problems in OT learning, joint learning of constraints and rankings seems to add unnecessary additional complexity.1 So we suppose that there are a finite set of constraints, and let $n$ be the cardinality of that set. If we put aside for now the contents of the lexicon (i.e., the set of URs), one can ask how many possible constraint rankings there are as a function of $n$.
Prince & Smolensky (1993), in their “founding document”, seem to argue that constraint rankings are total. Consider the following from a footnote:
With a grammar defined as a total ranking of the constraint set, the underlying hypothesis is that there is some total ranking which works; there could be (and typically will be) several, because a total ranking will often impose noncrucial domination relations (noncrucial in the sense that either order will work). It is entirely conceivable that the grammar should recognize nonranking of pairs of constraints, but this opens up the possibility of crucial nonranking (neither can dominate the other; both rankings are allowed), for which we have not yet found evidence. Given present understanding, we accept the hypothesis that there is a total order of domination on the constraint set; that is, that all nonrankings are noncrucial.
So it seems like they treat strict ranking as a working hypothesis. This is also reflected in the name of their method factorial typology, because there are $n!$ strict rankings of $n$ constraints. Roughly, they propose that one generate all possible rankings of a series of possible constraints, and compare their extension to typological information.2 In practice, as they acknowledge, OT grammars—by which I mean theories of i-languages presented in the OT literature—contain many cases where two constraints $c, d$ need not be ranked with respect to each other. For example, the first chapter of Kager’s (1999) widely used OT textbook includes a “factorial typology” (p. 36, his ex. 53) in which some constraints are not strictly ranked, and this is followed by a number of tableaux in which he uses a dashed vertical line to indicate non-ranking.3
Prince & Smolensky also acknowledge the existence of cases where there is no evidence with which to rank $c$ versus $d$. The situation is important because any learning algorithm which was trying to enforce a strict ranking of constraints would have to resort to a coin flip or some other unprivileged mechanism to finalize the ranking. Such algorithms are in principle possible to imagine, but neither the final step nor the postulate are motivated in the first place.
Prince & Smolensky finally admit the possibility of what they call crucial non-ranking, cases where leaving $c$ and $d$ mutually unranked has the right extension, but $c lt d$ and $d lt c$ both have the wrong extension.4 Such would constitute the strongest evidence for viewing OT grammars as weakly ranked, particularly if such grammars are linguistically interesting.
I will adopt the hypothesis of weak ranking; it seems unavoidable if only as a matter of acquisition. If one does, the set of possible rankings is actually much larger than $n!$. For example, for the empty set and singleton sets, there is but one weak ranking. For sets of size 2, there are 3: ${a lt b; b lt a; a, b}$. And, at the risk of being pedantic, for sets of size 3 there are 13:
- $a \lt b \lt c$
- $a \lt b, c$
- $a \lt c \lt b$
- $a, b\lt c$
- $a, b, c$
- $a, c \lt b$
- $b \lt a \lt c$
- $b \lt a, c$
- $b \lt c \lt a$
- $b, c \lt a$
- $c \lt a \lt b$
- $c \lt a, b$
- $c \lt b \lt a$
Already one can see that this is growing faster than $n!$ since $3! = 6$.
It is not all that hard to figure out what the cardinality function is here. Indeed, I think Charles Yang (h/t) showed this to me many years ago, and though I lost my notes and had to re-derive it, I’m reasonably sure he came up with is the same solution that I do here. This sequence is known as A000670 and has the formula
$$a(n) = \sum_{k = 0}^n k! S(n, k)$$
where $S$ is the Stirling number of the second kind. Expanding that further we obtain:
$$a(n) = \sum_{k = 0}^n k! \sum_{i = 0}^k \frac{(-1)^{k – i}i^n}{(k – i)!i!} .$$
This is a lot of grammars by any account. With just 10 constraints, we are already in the billions, and with 20 it’s between 2 and 3 sextillion. Yet this doesn’t look all that dramatically different than strict ranking when plot in log scale.
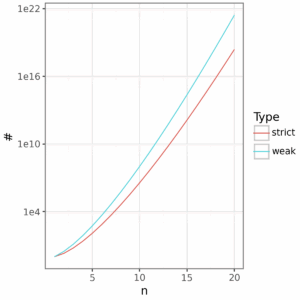
Clearly this is essentially infinite in the terminology of Gallistel and King (2009), and this ability to generate such combinatoric possibilities from a small inventory of primitive objects and operations is something that has long been recognized as a desirable element of cognitive theories. Of course, many of these weak rankings will be extensionally equivalent, and even others, I hypothesize, will probably be extensionally non-equivalent but extensionally equivalent with respect to some lexicon. None of this is unique to OT: it’s just good cognitive science.
Endnotes
- Note that the constraint induction of Hayes & Wilson (2008), for example, only considers a finite set thereof and therefore there does exist some finite set for their approach. The same is probably true of approaches with constraint conjunction so long as there are some reasonable bounds.
- Exactly how the analyst is supposed to use this comparison is a little unclear to me, but presumably one can eyeball it to determine if the typological fit is satisfactory or not.
- As far as I can tell, he never explains this notation.
- There is a tradition of using $\ll$ for OT constraint ranking but I’ll put it aside because $\lt$ is perfectly adequate and is the operator used in order theory.
References
Gallistel, C. Randy and King, A. P. 2009. Memory and the Computational Brain: Why Cognitive Science Will Transform Neuroscience. Wiley-Blackwell.
Hayes, B. and Wilson, C. 2008. A maximum entropy model of phonotactics and phonotactic learning. Linguistic Inquiry 39: 397-440.
Prince, A., and Smolensky, P. 1993. Optimality Theory: constraint interaction in generative grammar. Rutgers Center for Cognitive Science Technical Report TR-2.
Neural fossils
Neural network cognitive modeling had a brief, precocious golden era between 1986 (the year the Parallel Distributed Processing books came out) and maybe about 1997 (at which point the limitations of those models were widely known…though I’m little fuzzier about when this realization settled in). During that period, I think it’s fair to say, a lot of people got hired into the faculty, in psychology and linguistics in particular, simply because they knew a bit about this exciting new approach. Some of those people went on to do other interesting things once the shine had worn off, but a lot of them didn’t, and some of them are even still around, haunting the halls of R1s. I think something similar will happen to the new crop of LLMologists in the academy: some have the skills to pivot should we reach peak LLM (if we haven’t already), but many don’t.
When LLMing goes wrong
[The following is a guest post from Daniel Yakubov.]
You’ve probably noticed that industries have been jumping to adopt some vague notion of “AI” or peacocking about their AI-powered something-or-other. Unsurprisingly, the scrambled nature of this adoption leads to a slew of issues. This post outlines a fact obvious to technical crowds, but not business folks; even though LLMs are a shiny new toy, LLM-centric systems still require careful consideration.
Hallucination is possibly the most common issue in LLM systems. It is the tendency for an LLM to prioritize responding rather than responding accurately, aka. making stuff up. Considering some of the common approaches to fixing this, we can understand what problems these techniques introduce.
A quick approach that many prompt engineers I know think is the end-all be-all of Generative AI is Chain-of-Thought (CoT; Wei et al 2023). This simple approach just tells the LLM to break down its reasoning “step-by-step” before outputting a response. While a bandage, CoT does not actually inject new knowledge into an LLM, this is where the Retrieval Augmented Generation (RAG) craze began. RAG represents a family of approaches that add relevant context to a prompt via search (Patrick et al. 2020). RAG pipelines come with their own errors that need to be understood, including noise in the source documents, misconfigurations in the context window of the search encoder, and specificity of the LLM reply (Barnett et al. 2024). Specificity is particularly frustrating. Imagine you ask a chatbot “Where is Paris?” and it replies “According to my research, Paris is on Earth.” At this stage, RAG and CoT combined still cannot deal with complicated user queries accurately (or well, math). To address that, the ReAct agent framework (Yao et al 2023) is commonly used. ReAct, in a nutshell, gives the LLM access to a series of tools and the ability to “requery” itself depending on the answer it gave to the user query. A central part of ReAct is the LLM being able to choose which tool to use. This is a classification task, and LLMs are observed to suffer from an inherent label bias (Reif and Schwarz, 2024), another issue to control for.
This can go for much longer, but I feel the point should be clear. Hopefully this gives a more academic crowd some insight into when LLMing goes wrong.
References
Barnett, S., Kurniawan, S., Thudumu, S. Brannelly, Z., and Abdelrazek, M. 2024. Seven failure points when engineering a retrieval augmented generation system.
Lewis, P., Perez, E., Pitkus, A., Petroni, F., Karpukhin, V., Goyal, N., …, Kiela, D. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks.
Reif, Y., and Schwartz, R. 2024. Beyond performance: quantifying and mitigating label bias in LLMs.
Wei, J. Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., …, Zhou, D. 2023. Chain-of-thought prompting elicits reasoning in large language models.
Yao, S., Zhao, J., Yu, D., Shafran, I., Narasimhan, K., and Cao, Y. 2023. ReAct: synergizing reasoning and acting in language models.